
Storing SQL scripts in C# code - best practices and lessons learned
In this article we will be discussing what approaches are commonly used to store SQL scripts, alongside possible advantages and disadvantages for each option. After that, we will take a look at an approach that offers the best of both worlds.
The common approaches
With the rise ORM libraries such as EF, writing SQL by hand is getting less common than it used to be. Writing SQL scripts for a simple insert or update is a thing of the past for most developers. However, non-trivial queries are still something you should usually write by hand.
When writing SQL scripts, we need to store them somewhere. The two most common approaches are:
- Storing scripts in the database as stored procedures
- Storing scripts in the code as string literals
Let’s take a look at both of these approaches.
1. Storing scripts in the database as stored procedures
In a lot of enterprise solutions, you’ll find that SQL scripts are kept in the database as stored procedures. The code then calls on the stored procedure with the necessary parameters.
This way SQL is kept out of the code, which improves readability since we get things like syntax highlighting in an SQL editor, and we’re able to run the scripts directly in our editor to test them.
However this approach comes with several downsides:
- It’s hard to manage stored procedures across multiple environments or databases. Every time we change a stored procedure in our Development database, we’ll also need to update our Staging and Production databases. If we accidentally forget one, we could cause major issues.
- We can’t easily see the history of changes to our SQL. Once the stored procedure has been changed, we can’t look back to see what it looked like before our last change. We can look at a backup, but that’s not very fast or easy.
- Application logic can get fragmented. stored procedures can contain application logic. Meaning it’ll be a lot harder to follow the flow of our program when we’re debugging, since our logic is spread out across two systems.
The first two disadvantages can be solved by using third-party software, but these solutions aren’t cheap. The third one can’t be solved, and is a major drain on productivity when debugging.
2. Storing scripts in the code as string literals
Speaking from experience, during my career as a developer so far, I’ve seen SQL scripts stored as string literals in almost every code base I’ve worked on. Here are some examples:
var query = "SELECT Id, Name, Email, Adress FROM Users WHERE Id = @Id"
Can you determine what it’s supposed to do? Pretty easy right? @Id gets replaced by a value and the query returns Id, Name, Email and Address. But did you notice I made a mistake? I forgot the second d in Address.
Now take a look at this second example:
var query = "SELECT * FROM Orders " +
"INNER JOIN Products ON Order.ProductId = Products.Id " +
"INNER JOIN ProductCategories ON Products.categoryId = ProductCategories.Id " +
"INNER JOIN Users ON Users.Id = Orders.UserId " +
"WHERE Orders.CreatedDate BETWEEN @StartDate AND @EndDate AND Orders.Cancelled = 0 " +
"ORDER BY Orders.CreatedDate";
It’s still pretty straight-forward, but it’s a lot harder to read because there’s no syntax highlighting. I’ve seen code that has +100 line queries stored in strings. Try making sense of those without any formatting or highlighting.
Even worse, if we want to test the query, we have to copy and paste it into an SQL editor and remove all those nasty quotes and other added symbols. And to copy it back into our code, we have to do the exact opposite and add everything again!
Looking at the examples above, we can list the following disadvantages of storing our queries as string literals:
- Storing your SQL in strings makes it hard to spot mistakes. Are you able to easily determine what this SQL does? Are there any typo’s? Both questions are harder to answer than they should be.
- Debugging and testing SQL stored in a string requires you to ‘clean it up’. You’ll have to copy and paste it to an SQL editor, remove all the double quotes, plus signs, etc… A lot of work before you can even start to think about what might be wrong with the code itself. And removing or adding all those extra symbols can easily result in unnoticed errors!
It isn’t all bad though. Since we’re storing these scripts in our code, we can use Git to keep track of changes and we’re able to merge our changes to other branches and deploy to other environments. No need for expensive third-party software. Also, all our application logic is forced to stay inside our code base.
But surely, there must be a better way?
Best of both worlds
Now that we know the advantages and disadvantages of both of the most common approaches, It’s pretty hard to choose between them. Because both options have some serious downsides.
But they were all of them deceived for a third option was made!
We can store our scripts in individual SQL files inside our code base. This will grant us the advantages of both Stored Procedures and storing our SQL in our code base, without any of the disadvantages we listed before.
- SQL formatting and syntax highlighting. Because we’re using dedicated SQL files, our IDE allows us to connect directly to the database. Now we can use things like auto-formatting and syntax highlighting while writing our scripts, resulting in less typos and syntax mistakes.
- Easy debugging directly on the database. We can run our queries directly out of our IDE and immediately see the results. Making debugging and development a lot easier.
- The history is kept in Git. Our SQL is stored in Git, so we can keep track of their history. No more looking through database backups.
- Deploys with the rest of the code base. There’s also no need anymore to manually update scripts across different environments.
But what about reading those files? Won’t we have to read them from our disk? No, because we are using a resource file or ‘resx’ file that contains the SQL files. We’ll add those files as an embedded resource. This way we can retrieve the file contents during runtime and with minimal effort.
How to set things up
Below I’ll show you how to set all of this up. I’ll be using Dapper in the example. You can find all the code in an example project on my GitHub page if you would like to try it out for yourself: https://github.com/nstubbe/StoringSqlFilesInResources
- Create the GetUserQuery class. This class will handle setting up the connection to the database and executing the query. Notice the value assigned to _query. This is a combination of the name of the resource file, followed by the filename of our SQL file.
// GetUserQuery.cs
public class GetUserQuery
{
private string _query = SqlScripts.GetUserQuery;
public async Task<User> Execute(int userId)
{
using (var connection = new SqlConnection("MyConnectionString"))
{
var user = await connection.QuerySingleAsync<User>(_query, new{userId});
return user;
}
}
}
- Create the GetUserQuery.sql file
// GetUserQuery.sql
SELECT Id, Name, Email, Address
FROM Users
WHERE Id = @Id
- Create a resource (.resx) file. I’m calling my file SqlScripts.resx. Since I’m using Visual Studio, I’m just right clicking the project and selecting Add Item. In the following popup I select a resource file and enter the filename.
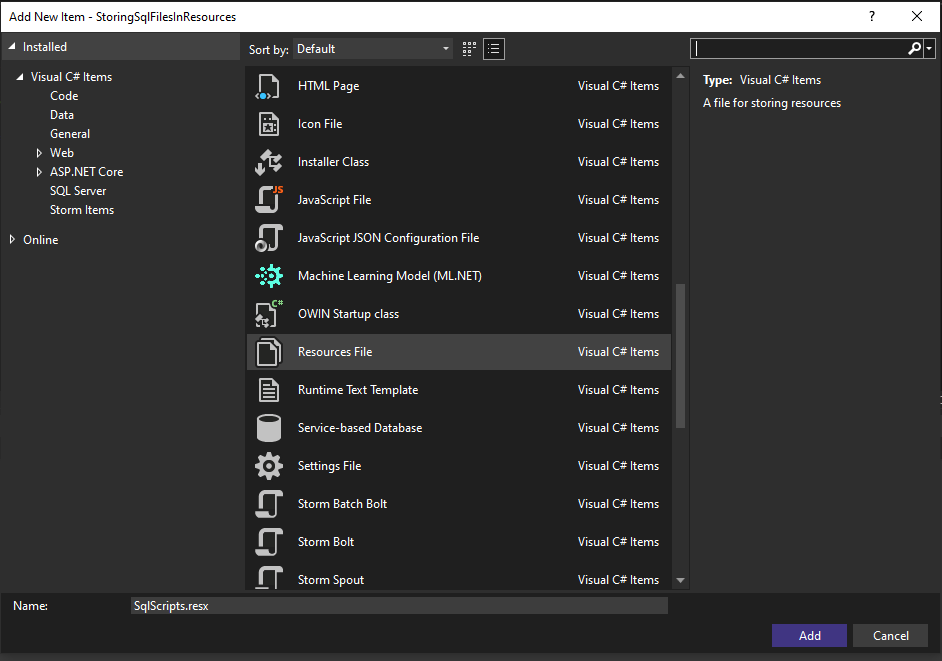
- The resource file should have automatically opened when you created it, if not open it now. You’ll see the following screen:
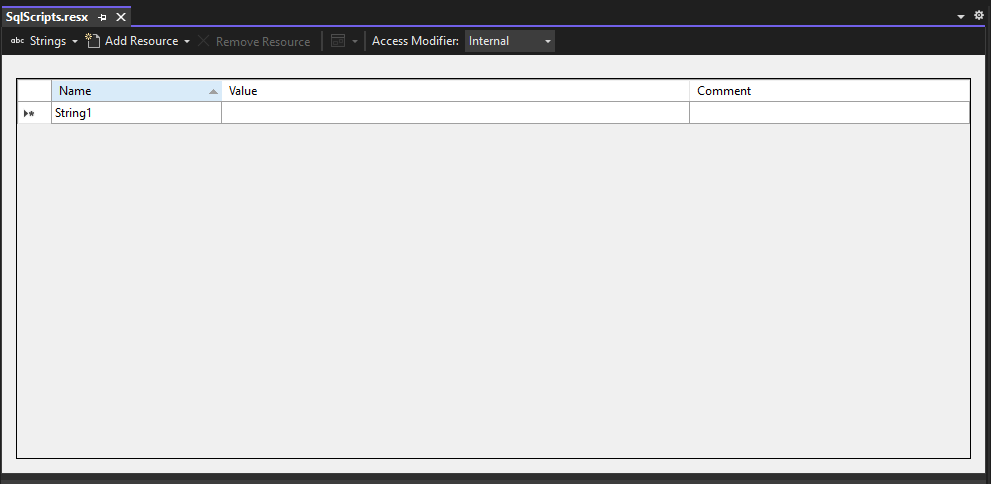
- Change the resource type from Strings to Files at the top left of the window.
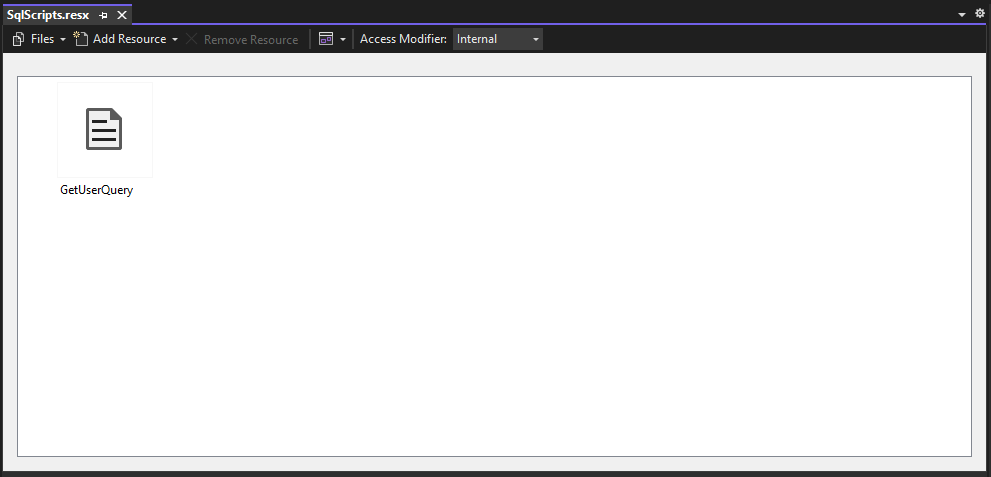
- Now click Add Files. An explorer window will open.
- Go to the correct folder where your SQL file is located, and double click to add it to your resource file. If the SQL file isn’t visible, make sure the extension filter on the bottom says All Files instead of just Text Files. Once added, you should be looking at something like this:
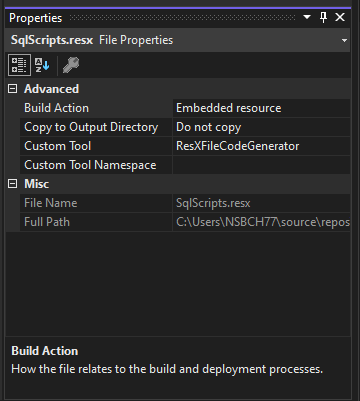
- And finally, configure the resource file as an embedded resource. This way we can call our SQL files at runtime. To do this, just right-click your resource file in your solution explorer, and choose Properties. Now set the build action to embedded resource.
- Done! You can add as many scripts as you want to the resource file we created, and they’ll all be available at runtime.
Thanks for reading! If you would like to stay up-to-date with my blog, consider subscribing to the codecrash newsletter. You'll receive an email whenever I publish a new article.